MHServerEmu Progress Report: April 2024

Another month has passed, and we have some more updates to share regarding the development of MHServerEmu.
I, Serialize
Communication is key in relationships, and the one between the client and the server is no exception. A very important aspect of computer communication is the process of serialization - describing a data structure or an object so that it can be restored at another time and/or place. Serialization is commonplace in games: every time you save or load, you are serializing or deserializing the state of the game. Refactoring and improving our server’s serialization capabilities is something I have spent the better part of April working on. Before we dive into the specifics of what exactly Gazillion concocted, let us take a look at the bigger picture first. Some of this has already been mentioned in previous reports, but this time we are diving deeper than ever before.
One of the most popular serialization formats these days is JSON: it represents data as plain text, which makes it easily readable and convenient to edit, but also highly inefficient both in terms of bandwidth and serialization time. As mentioned in previous reports, the core technology that Marvel Heroes relies on for serialization is Google’s Protocol Buffers (protobufs). Here is how it works: first, you define a structure using its language:
message NetStructItemSpec {
required uint64 itemProtoRef = 1;
required uint32 itemLevel = 2;
required uint64 rarityProtoRef = 3;
required uint32 seed = 4;
optional uint32 creditsAmount = 5;
repeated NetStructAffixSpec affixSpecs = 6;
optional uint64 equippableBy = 7;
}
Then, you run the structures you defined through a code generator that produces highly efficient, but also very repetitive and barely readable code in your desired programming language. You can add this code to your program as a library, and then call it when you need something serialized. An important aspect of the code produced this way is that it includes the so-called “descriptors” that contain real-time type information (RTTI) and can be parsed by special tools, such as protod, to restore the original definitions. This is exactly what we did: we reconstructed the original protobuf structures from the compiled C++ client code, which we then used to generate a C# library that serializes data in a way the client can understand. Such language interoperability is one of the key features of protobufs.
One way Gazillion uses protobufs is to implement a system that resembles the command pattern, and is the foundation of all network messages: requests are represented as objects that are serialized using protobufs, and then sent over a network. Here is an example of a server to client message that includes the NetStructItemSpec structure from the previous example, and is used to broadcast chat messages when players find rare items:
message NetMessageBroadcastRareItem {
required string playerName = 1;
required NetStructItemSpec item = 2;
required ChatRoomTypes roomType = 3;
}
And this is where the intended use of protobufs ends and we get into the hackery territory. As you look through the defined messages, you begin to see things like this pop up:
message NetMessageEntityCreate {
required bytes baseData = 1;
required bytes archiveData = 2;
}
message NetMessageLocomotionStateUpdate {
required bytes archiveData = 1;
}
message NetMessageActivatePower {
required bytes archiveData = 1;
}
message NetMessagePowerResult {
required bytes archiveData = 1;
}

To make sense of this, first, we need to understand how protobufs work under the hood. Note: We are going to assume little-endian byte order unless noted otherwise.
At the heart of protobufs lies the so-called wire format, which is used to encode your defined structures as binary data. The basic unit of information in protobufs is called a varint, which stands for variable-width integer. Typically, when you want to store a value, you use a data type with a certain amount of memory allocated to it, which dictates its bounds: a classic example of this is a signed 32-bit integer, which can store values from -2147483648 to 2147483647. When you store smaller values, you may need just one or two bytes, but a 32-bit signed integer is still going to use all four of them, even though most of the bits are going to be left unset. Protobufs solve this problem in two steps. First, when varints are encoded, the most significant bit in each byte is reserved as the “continuation bit” that determines whether there are more bytes that follow it:
10010110 00000001
^ MSB ^ MSB
When decoding, we continue to read bytes until we get to the one where the most significant bit is not set. This way we can encode a value equivalent to a 64-bit unsigned integer, and it is going to take from one to ten bytes, with smaller values using fewer bytes.
If you were to use this approach to encode a signed integer though, you would run into an issue: since the most significant bit of an unencoded signed integer is used to determine whether it is negative or not, you are going to have go through a bunch of mostly useless zeroes to get to it, and you will end up using all ten bytes even for a value as small as -1. This is where the second part of the protobuf magic comes in: zig-zag encoding. The idea is that you mix positive and negative values together in a “zig-zag” pattern, with even numbers representing positive values, and odd numbers representing negative values:
Encoded Decoded
0 0
1 -1
2 1
3 -2
4 2
One last piece of the original protobuf puzzle we need to understand is how floating point values are encoded. Here a simple pointer hack is used: we just reinterpret the same four bytes used to store a 32-bit float as an unsigned 32-bit integer, and then we encode it using the method above.
Now that we have experienced the tragic backstory flashback, we can take a look at Gazillion’s secret serialization sauce. It seems they were unhappy with how protobufs performed out of the box, so they created their own custom abstraction layer on top of the base protobuf wire format - archives. An archive is an object that combines a memory buffer with functionality for four modes of serialization:
-
Migration: for server <-> server serialization.
-
Database: for server <-> database serialization.
-
Replication: for server <-> client serialization.
-
Disk: for server <-> file serialization.
Each mode can be used both for packing and unpacking, so in total we actually have eight different modes. To interact with an archive, we use the Transfer() method that has overloads for most common primitive types, such as bool, int, float, and so on, but also structures like Vector3, collections, and objects that implement the ISerialize interface:
interface ISerialize
{
public bool Serialize(Archive archive);
}
Most Transfer() overloads act as wrappers than convert the passed value to or from an unsigned integer, and serialize it as a varint using the internal Transfer_() method:
public bool Transfer(ref int ioData)
{
if (IsPacking)
{
// Convert int to uint and write it
uint encodedData = CodedOutputStream.EncodeZigZag32(ioData);
return Transfer_(ref encodedData);
}
else
{
// Read a uint and convert it back to int
uint encodedData = 0;
bool success = Transfer_(ref encodedData);
ioData = CodedInputStream.DecodeZigZag32(encodedData);
return success;
}
}
In addition to the protobuf wire format, Gazillion brought some of their own tricks to the table. For instance, along with the standard protobuf way of encoding floating point values, archives support another, more efficient, but less precise way:
public bool TransferFloatFixed(ref float ioData, int precision)
{
precision = precision < 0 ? 1 : 1 << precision;
if (IsPacking)
{
uint encodedData = CodedOutputStream.EncodeZigZag32((int)(ioData * precision));
return Transfer_(ref encodedData);
}
else
{
uint encodedData = 0;
bool success = Transfer_(ref encodedData);
ioData = ((float)CodedInputStream.DecodeZigZag32(encodedData)) / precision;
return success;
}
}
A precision argument is passed, which represents the power of 2 by which the value is multiplied. The fractional part is then discarded, and the value is encoded as a regular signed integer using the zig-zag method. The process is reversed to get an approximation of the original value with the given precision. Here is an example of a real value being encoded:
// Encode
float value = 12.3689f;
value = value * (1 << 3); // 12.3689 * 8 = 98.9512
uint encodedValue = (uint)value; // 98
// Decode
value = (float)encodedValue / (1 << 3); // 98 / 8 = 12.250
So we end up with a value of 12.250, which is an approximation of the original 12.3689. The main use case for this kind of encoding is efficiently packing Vector3 and Orientation structures, which consist of multiple float values, and reducing the amount of network traffic used by systems like locomotion.
The final boss of these encoding strategies is the way bool values are encoded. This caused us a lot of headaches when we first started the development of this project. The boolean data type represents a binary value that can be either true or false. However, since the smallest addressable unit of memory in many computer architectures is a byte, which consists of eight bits, a bool value typically occupies eight times more memory than it actually needs.
To deal with this inefficiency, Gazillion implemented a custom format for packing multiple boolean values into a single byte. When you first attempt to write a bool to an archive, it writes a byte and remembers the offset at which it was written. If the value is true, it writes 0x81, otherwise 0x1. The next time you try to write a bool, the archive goes back to the offset of the previously written bool byte, and packs the additional value into it. This continues until the archive packs up to five values to that byte, after which it writes a new byte and updates the offset. The end result you end up with is what we used to call “phantom bools”: when you read encoded data back, each boolean-packed byte contains up to four extra values in addition to the one that was being transfered in that Transfer() call. Here is how it ends up being structured:
Bits | Num Encoded | Hex | Values
10000 | 001 | 0x81 | true
00000 | 001 | 0x1 | false
11000 | 010 | 0xC2 | true, true
01000 | 010 | 0x42 | false, true
00000 | 011 | 0x3 | false, false, false
10100 | 011 | 0xA3 | true, false, true
11111 | 101 | 0xFD | true, true, true, true, true
Each primitive data type may also use alternative encoding methods depending on the mode of serialization. The examples above are all for the replication mode, which we have to reimplement as accurately as possible, because it is the mode used to communicate with the client. Since we have the full control of the backend, for other modes, such as database, we can either reuse replication encoding, or come up with some kind of custom solution.
With the theory out of the way, we arrive at the practical application of archives. This is done via the previously mentioned ISerialize interface. It is implemented by objects that need to be serialized to archives, and when the stars align it looks like this:
public bool Serialize(Archive archive)
{
bool success = true;
success &= archive.Transfer(ref _currentCount);
success &= archive.Transfer(ref _totalCount);
success &= archive.Transfer(ref _timeStart);
success &= archive.Transfer(ref _timeEnd);
success &= archive.Transfer(ref _timePaused);
return success;
}
This code handles both serialization and deserialization in all modes, it is easy to read and maintain, and in general it looks like a good time. However, the saying “no plan survives contact with the enemy” is very true here. A lot of ISerialize implementations in the game look a lot more like this:
public bool Serialize(Archive archive)
{
bool success = true;
uint numElements = (uint)_myList.Count;
archive.Transfer(ref numElements);
if (archive.IsPacking)
{
if (archive.IsPersistent)
{
// server -> database serialization
}
else if (archive.IsReplication && archive.ReplicationPolicy.HasFlag(AOINetworkPolicyValues.ReplicateToProximity))
{
// server -> client serialization
}
}
else
{
if (archive.IsPersistent)
{
// database -> server deserialization
}
else if (archive.IsReplication && archive.ReplicationPolicy.HasFlag(AOINetworkPolicyValues.ReplicateToProximity))
{
// server -> client deserialization
}
}
return success;
}
Everything ends up being completely mixed up and coupled together, which makes it the opposite of a good time. However, these messy implementations provide us with a valuable insight into how the backend of the game, including database persistence, worked. Essentially, your account data, heroes, items, and so on would be serialized to an archive in the database mode to get what was pretty much a save file. This save file would then be saved to the database as a blob data type.
All the necessary migration between versions would be handled by the same Serialize() method during unpacking, meaning that implementations also had to include additional complexity overhead of all the patches ever released so that someone who played for a week in 2013 could still log in again in 2017, with all their progress preserved and migrated on login. Thankfully, we do not have any old saved data to account for, and even when we do implement the support for more versions of the game, we can handle this conversion with an external tool of some kind if the need arises.
archiveData byte arrays mentioned when I was talking about protobuf network messages are actually these same “save files”, but serialized in replication mode, which includes additional runtime information that is generally omitted from persistent storage, as well as some other differences. Some of these messages were actually standard protobuf structures prior to version 1.25, in which the developers did an optimization pass of their network protocol that included the conversion of some of the standard protobuf messages to archives. Good examples of this are NetMessageLocomotionStateUpdate and NetMessagePowerResult: rather than representing an object, they are used as a more efficient way of packing runtime information. Here is an example of what NetMessagePowerResult looked like in version 1.24:
message NetMessagePowerResult {
required uint64 powerPrototypeId = 1;
required uint64 targetEntityId = 2;
required uint64 flags = 3;
optional bool isSelfTarget = 4;
optional uint64 powerOwnerEntityId = 5;
optional uint64 ultimateOwnerEntityId = 6;
optional uint64 combinedOwnerEntityId = 7;
optional float damagePhysical = 8;
optional float damageEnergy = 9;
optional float damageMental = 10;
optional float healing = 11;
optional NetStructPoint3 powerOwnerPosition = 12;
optional int64 powerAssetRefOverride = 13;
optional uint64 transferToEntityId = 14;
}
So what I have been spending most of April doing is painstakingly going through all classes the implement the ISerialize interface, untangling the mess, and making adjustments to structures of serializable objects as needed. All of this is a necessary step for implementing the area of interest (AOI) system that handles replication of the server-side simulation to clients, but this is a story for another time.
Time is a Flat Circle
Serialization is not the only issue I have been tackling lately. As we get more and more fundamental systems working, we get closer to the real meat of this project - the real-time simulation of the game world, and the “real-time” aspect of it is quite tricky.
Probably the most ubiquitous programming pattern you can see in video games is the game loop. In its most simplest form it looks like this:
while (true)
{
ProcessInput(); // Get input from keyboard / mouse / controllers
Update(); // Update the simulation accordingly
Render(); // Render the new state of the simulation
}
Since we are dealing with a server, there are some I/O differences, but the general idea is the same:
while (true)
{
ProcessClientMessages(); // Player input is serialized and sent over a network
Update(); // Update the simulation accordingly
SendUpdatesToClients(); // "Render" the new simulation state to clients
}
We still process player input, even though we receive it with a delay, we update the simulation accordingly, and then we “render” the results, but instead of outputting a frame buffer to a screen we send message packets over a network. Therefore, most common wisdom regarding game loops is applicable to our case as well.
The big problem with this simple loop is that it runs as fast as your computer can run it. Therefore, the game is going to slow down or speed up depending on the processing power of the computer running it. It is not 1990 anymore, and our computers generally no longer have turbo buttons to account for this, so we have to deal with it in software.
One common way of solving this is to introduce the so-called delta time - the time difference in seconds between the previous update and the current one:
float _lastFrameStartTime;
while (true)
{
float currentTime = GetTime();
// Divide to convert milliseconds to seconds
float delta = (currentTime - _lastFrameStartTime) / 1000f;
_lastFrameStartTime = currentTime;
ProcessInput();
Update(delta);
Render();
}
And then when we update something, we multiply our time-sensitive values by delta to account for how much time has passed:
float _position;
float _speed;
void Update(float delta)
{
_position += _speed * delta;
}
So the less time has passed since the last update, the less distance we are going to cover in this update. This works great if the game is running locally, and it is the approach you are most likely familiar with if you have ever worked with popular game engines. However, it is not a one-size-fits-all solution. One issue with it is that most video games rely on single-precision floating-point numbers (floats) for a lot of their calculations, which are fast, but also subject to rounding errors. The faster your computer runs, the more updates that involve float calculations it does, and the more float calculations it does, the more its rounding error builds up. In online multiplayer games this leads to clients getting desynchronized from the server, which is something that should be minimized.
To avoid this issue, a fixed update interval is used, commonly referred to as a “tick rate”. This is especially a hot topic in competitive shooters, where the tick rate can get as high as 120+ Hz (so 8.33 ms or less per simulation update). The rendering frequency in this case is generally decoupled from the main simulation, so it is possible to render the game at hundreds of frames per second even with a modest tick rate. The smoothness in this case is achieved by a combination of interpolation and independent simulation of systems that do not have synchronized, such as particle effects. A good example of this is Overwatch, which at launch ran at a modest (by competitive shooter standards) tick rate of around 21 Hz, and eventually it got upgraded to approximately 63 Hz in a later patch. The biggest downside of a low tickrate is that it “batches” events together, causing some things that occured separately to be processed simultaneously, such as you and your opponent shooting and killing each other.
Marvel Heroes also uses this approach: internally it refers to its ticks as “frames”, and by default it runs at the “framerate” of exactly 20 Hz (50 ms per frame). The code that runs the simulation is shared by both the server and the client: the server runs it as a standalone thing, while in the client it is integrated into Unreal Engine, so essentially you have a mini-engine running inside Unreal. To keep the gameplay smooth and responsive, the client runs its own instance of the simulation and corrects it using the information that the server “renders” to it.
So what do you do after you finish your fixed-time update? You wait until it is time for another update. The naive way to approach it is this:
const float TargetFrameTime = 50.0f;
float _previousTime;
float _accumulatedTime;
while (true)
{
float currentTime = GetTime();
_accumulatedTime += currentTime - _previousTime;
_previousTime = currentTime;
if (_accumulatedTime >= TargetFrameTime)
{
_accumulatedTime -= TargetFrameTime;
DoFixedTimeUpdate(); // Process input, update state, send updates
}
}
While precise, doing it this way keeps the thread constantly busy, wasting power doing pretty much nothing. Thankfully, there is a handy tool provided to us by the operating system - sleep, which is a feature that lets the OS know that we are not currently doing anything, and the CPU can be used for something else, or it can stay idle if nothing else is going on. This provides us with a much more efficient, but still rather naive way of implementing this, which we previously used for MHServerEmu:
while (true)
{
float currentTime = GetTime();
_accumulatedTime += currentTime - _previousTime;
_previousTime = currentTime;
if (_accumulatedTime < TargetFrameTime)
{
float sleepTime = TargetFrameTime - _accumulatedTime;
// Sleep() takes an integer number of milliseconds as its argument
Thread.Sleep((int)sleepTime);
continue;
}
// Do the update if enough time has passed
}
So what is so naive about this? The fact that the thread scheduler treats what you tell it to do like the pirate code: it is more like guidelines than actual rules. The time you specify is actually the minimum amount of time the thread is going to sleep, and how much it overshoots this target depends on: your operating system and its version, your hardware, whether a high precision timer is enabled, ambient entropy levels, the state of Schrödinger’s cat, and who knows what else.
This is a problem we are still working on solving, but the solution we are trying out at the time of writing is one of multiple used by the MonoGame framework (a modern offshoot of Microsoft’s XNA), which involves sleeping in smaller intervals with checks inbetween:
while (true)
{
float currentTime = GetTime();
_accumulatedTime += currentTime - _previousTime;
_previousTime = currentTime;
if (_accumulatedTime < TargetFrameTime)
{
if (TargetFrameTime - _accumulatedTime >= 2.0)
Thread.Sleep(1);
}
// Wrap this in while loop to catch up if we missed some frames
while (_accumulatedTime >= TargetFrameTime)
{
_accumulatedTime -= TargetFrameTime;
DoFixedTimeUpdate();
}
}
The results we have seen with this implementation range from “good enough” to “pretty great”. When testing on a virtual machine running Kubuntu, the overshoot was generally within our leeway of 2 ms, while on Windows 10 our measured sleep times seemed to be around 15 ms (given the requested 1 ms of sleep), which appears to match the default Windows timer resolution. For measuring this we have used the Stopwatch class provided by .NET. For now this seems to be accurate enough for our 50 ms window, but for potentially running a more precise simulation we are going to need a better solution.
There are still some tricks we can try out, including those employed by MonoGame and its cousin FNA, such as importing and calling native Windows API functions related to timer resolutions, making use of Thread.SpinWait(), and others. As more gameplay systems become functional, we are also going to have to improve our catchup system: fixed-time update systems are prone to so-called “death spirals”, where your computer is unable to update the simulation fast enough, which leaves more work to do for the next update, and eventually it ends up getting completely stuck. There are strategies to mitigate and potentially recover from these, and it is something we are going to dive deeper in the future.
Navi, Population, and Physics
AlexBond is back yet again to discuss how things have been going on his front. Please see the March report for more context on the work he has been doing lately.
Hey everyone, it’s AlexBond. This month has ended up being rather fruitful, although it may not seem this way at first. Let’s take a look.
Here are the main things I have been working on:
-
Finishing up the NaviSystem
-
BlackOutZone
-
PropSets
-
AreaPopulation
-
SpawnSpec
-
PlayKismetSeq
-
EntityFilter Evaluate
-
PhysicsManager and NaviSweep
NaviSystem has been improved: all issues have been fixed, and we now have the NaviMesh.Contains() function that we can use to determine whether an object is contained within the playable area or not. One of the issues that has been fixed is the spawning of NPCs outside of the playable area. In addition, this has laid the foundation for processing game physics interactions.
A BlackOutZone is a marker with a radius that defines a zone where enemy spawning is restricted. This information is contained within Cell markers. Some blackout zones are defined in missions or spawners, and NPCs can spawn only if the required mission is in the correct state. When all markers are placed via SpawnBlackOutZone(), we get another tool to detect intersections with a zone - InBlackOutZone(). This adds another check when spawning ClusterEntities.
PropSets are sets of random destructible objects that appear in an area, such as boxes and cars. Markers are picked using GetRandomPropMarkerOfType() from PropShapeLists, and then placed in the world. We now have even more cars and trash!
AreaPopulation is another way of spawning enemies in the game world, but in this case instead of markers we have groups and their weights. Each area has an AreaPrototype.Population field that contains Themes.Enemies, as well as population density parameters. We calculate the density of enemies that are already present in an area, and then we determine how many additional enemies we need to add to get to the defined threshold. To get a more accurate density value we use CalcSpawnableArea() via NaviMesh while taking into account space not occupied by blackout zones. This way enemies are distributed randomly and evenly along appropriate cells using SpawnInCell(). Examples of regions that rely on this spawning method include Training Camp, Daily Bugle, Classified Bovine Sector, almost all terminals, as well as other regions that previously seemed rather deserted.

Fun fact: the terminal version of Sinister Lab has a population override that prevents dinosaur enemies from spawning there, even though they are present in the story mode version of this region. Some players didn’t seem to remember this.

SpawnSpec is a class responsible for spawning all groups of enemies, including regular NPCs that are typically tied to missions or their own spawners. By merging the spawning system into the SpawnSpec class we have finally been able to get rid of issues with objects hovering in the air and getting stuck in the ground. One remaining problem is that because many destructible props currently spawn after enemies, the system is unable to properly detect collisions, which leads to enemies getting stuck in cars and barrels. This is going to be resolved on its own once spawners get their own timers and events for doing their work.
PlayKismetSeq is a command that can be sent as a message to the client to start a scripted Unreal Engine cutscene. For example, I have added a trigger for such sequence to the Raft, and now you can see the Quinjet landing when you load into the region. This also includes an animation of Juggernaut running away.
Editor’s Note: Kismet is the name of the visual scripting language that was available in Unreal Engine 3. Those of you who have experience with versions 4 and 5 are most likely familiar with Blueprints: Kismet is an earlier iteration of the same concept. For more information on Kismet see the official documentation. And now, back to our regularly scheduled programming.

After that I started investigating what triggers these sequences, and that led me to hotspots and MissionConditionPrototype.

Everything turned out to be more complicated than I expected, and I ended up working on implementing mission logic and game physics…
EntityFilters are sets of conditions for triggering mission events. To get the result of a condition it has to be determined using the Evaluate() function, as well as a cached EntityTrackingContextMap in the InteractionManager. This function is coupled with lots of various systems: regions, areas, entities, missions. I have implemented all the base logic, and this foundation is going to come in handy in the future.
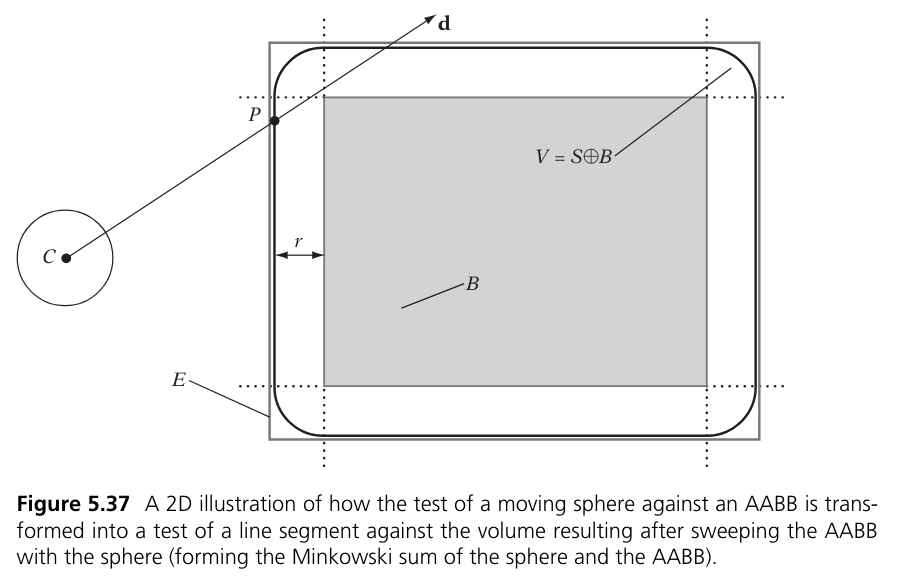
The PhysicsManager calculates displacements and collisions. The server runs PhysicsResolveEntities() every frame and checks all active entities for collisions. Internally displacements are called sweeps, and they are handled by the NaviSweep class. NaviSweep consists of numerous real time calculations. After studying some of them, we were able to figure out the source of inspiration for many of them: the book Real-Time Collision Detection by Christer Ericson. Many of the functions used in the game are taken from this book word for word, and it has helped us to make sense of everything. Below is a figure from the book that explains how the Sphere.Sweep(Aabb) function works.
PhysicsManager and NaviSweep do a lot of projection and collision detection, but the end result of all these calculations is the triggering of these three events:
-
OnCollide() -
OnOverlapBegin() -
OnOverlapEnd()
We now have triggers, we can check conditions with Evaluate(), but we still don’t have an avatar that is going to interact with all of these.
For an avatar (a playable character) to be able to enter the physical world and interact with it, it requires a working Locomotor system.
The server runs LocomoteEntities() every frame to calculate all types of movements in the game. The Locomotor system is responsible for things such as: moving enemies with MoveTo(), finding their paths with GeneratePath(), rotating them with LookAt(), processing flight, various restrictions, velocity, synchronizing these movements between the server and the client with SetSyncState(), as well as interacting with the NaviPath system. And this is what I am going to be working on next month!
We hope you enjoyed this report, see you again next time!